Очень важная статья, в которой описывается область знаний hr аналитики, которую нужно если не знать для применения, но хотя бы понимать с тем, чтобы общаться с аналитиком.
Это перевод статьи 9 HR Analytics terms you should know. Перевод выполнила студентка Высшей Школы Экономики Венская Диана.
Когда мы говорим про аналитику HR данных, мы используем такие слова как машинное обучение, алгоритмы и интеллектуальный анализ данных. Однако, понимаем ли мы на самом деле значения этих слов? Честно говоря, когда я впервые их услышал, я не понимал… Этот блог расскажет о нескольких наиболее используемых терминах в HR аналитике данных.
В своем предыдущем блоге про прогнозирующую аналитику в HR я рассказывал о концепции дерева решений на примере: я попытался предсказать, будут ли дети играть на улице на основе четырнадцатидневного метеорологических прогнозах. Это дерево решений выглядело следующим образом:

Если эти два набора данных не разделяются, то проверять точность созданных моделей будет необходимо на тех же данных, которые были использованы для создания алгоритма в первую очередь. И это фундаментальная ошибка, которая может привести к тому, что называется «переобучением».

Поэтому не поддавайтесь тому обману, когда люди говорят, что у них есть прогностическая модель, которая может создать очень точные прогнозы! Под «капотом» данная модель, вероятно, не имеет такой ценности.
Это перевод статьи 9 HR Analytics terms you should know. Перевод выполнила студентка Высшей Школы Экономики Венская Диана.
9 терминов HR аналитики, которые необходимо знать
Когда мы говорим про аналитику HR данных, мы используем такие слова как машинное обучение, алгоритмы и интеллектуальный анализ данных. Однако, понимаем ли мы на самом деле значения этих слов? Честно говоря, когда я впервые их услышал, я не понимал… Этот блог расскажет о нескольких наиболее используемых терминах в HR аналитике данных.
1. Интеллектуальный анализ данных (Data mining)
Интеллектуальный анализ данных похож на процесс поиска золота. Золотоискатели просеивают кучу грязи и камней в надежде обнаружить хотя бы кусочек блестящего/сияющего золота. Интеллектуальный анализ данных - это процесс обнаружения каких-либо зависимостей в куче сырых необработанных данных и превращения их в ощутимую информацию, которая, в свою очередь, может использоваться для прогнозирования поведения в реальной жизни или реальных событий. Примечательно, что 99,5% всех данных в мире никогда даже не анализировались.2. Машинное обучение
Машинное обучение – техника, которая, как правило, используется в процессе интеллектуального анализа данных. С помощью данной техники машина (компьютер) будет изучать ваши данные, анализируя их и распознавая закономерности. Это говорит о том, что машинное обучение можно рассматривать как форму искусственного интеллекта (ИИ), поскольку он обеспечивает компьютеры нужными инструменты, которые необходимы им для сбора и включения новой информации.3. Дерево решений
Как я объяснял в предыдущем блоге, дерево решений - это модель, которая выглядит как дерево и состоит из решений и их возможных последствий. Это полезный инструмент для прогнозирования (ближайшего) будущего. Дерево решений позволяет предсказывать, что может произойти при изучении существующих данных. Это очень похоже на то, как каждый учится на основе своего прошлого опыта. В дереве решений каждое решение представляет собой толстую ветвь и каждый результат решения – тонкие ответвления.В своем предыдущем блоге про прогнозирующую аналитику в HR я рассказывал о концепции дерева решений на примере: я попытался предсказать, будут ли дети играть на улице на основе четырнадцатидневного метеорологических прогнозах. Это дерево решений выглядело следующим образом:
Это дерево демонстрирует то, что дети, скорее всего, будут играть на открытом воздухе, когда прогноз говорит о солнечной погоде (да). Когда прогнозируется дождь, то дети вряд ли будут играть на отрытом воздухе (нет). Это дерево решений было создано с использованием Weka, бесплатного приложения для интеллектуального анализа данных, прогнозирующая точность которого равна 71%.


4. R
Многие HR специалисты часто используют Excel. Однако, большинство специалистов из области прогнозирующей HR аналитики используют R. R, вероятно, самый популярный инструмент для аналитиков. R - (бесплатная) система с открытым исходным кодом для статистических вычислений и визуализации. Он также позволяет работать с массивными наборами данных, которые будут слишком объемными для их обработки в Excel.
5. Структурированные vs. неструктурированные данные
Мы много говорим о данных. В данных есть два различия. Когда они аккуратно оформлены в электронной таблице или в базе данных, и это называется структурированными данными. Например, HR знает имена своих сотрудников, их возраст, где они живут, в каком отделе они работают, как они работают и т. д. Все эти данные структурированы: просмотрев на имя или идентификатор, можно легко найти информацию о человеке.
Противоположными являются неструктурированные данные. Отсутствие структуры требует определенного количества времени и энергии для приведения данных в порядок. Возьмем, например, электронные письма. Невозможно точно упорядочить электронную почту по теме или содержанию (следовательно, она не структурирована). Эти данные, прежде всего, должны быть структурированы перед тем, как их можно будет проанализировать.
6. Контролируемое vs. неконтролируемое обучение
В контролируемом машинном обучении подразумевается вывод выходных данных, что означает, что у компьютера есть данные, на основе которых он может обучаться. Например, если вы хотите предсказать возможность добровольного ухода, самый простой способ - позволить компьютеру обучаться на прошлом. В контролируемой модели компьютер анализирует данные людей, которые добровольно покинули компанию. Затем он сравнивает эти данные с людьми, которые в тот момент времени остались в компании. Эта информация сообщает компьютеру, кто покинул компанию, а кто – нет, и позволяет ей создать прогностическую модель сотрудников, которые могут уйти. Это пример контролируемого машинного обучения.
В неконтролируемом обучении нет вывода выходных данных. Система все еще может продолжать делать прогнозы на основе этих данных, группируя множество связанных данных. В следующем примере вы увидите, как работает контролируемая кластеризация.
7. Кластеризация
Кластеризация - это вид машинного обучения, который строит прогнозы путем кластеризации данных.
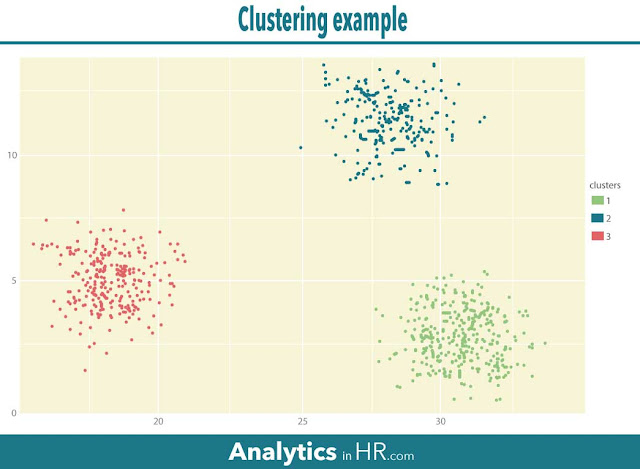
Кластеризация данных подразумевает под собой процесс, при котором компьютер ищет и рассматривает группы, которые имеют некоторое сходство. В следующем примере показаны 1000 аспектов данных, которые разделены на три кластера. Это пример, который наглядно дает представление о том, какие данные принадлежат к какому кластеру.

Машинное обучение позволяет оценивать различные кластеры. Кроме того, когда вводятся новые данные, алгоритм может предугадать, к какому кластеру они больше относится. Данные в правом нижнем углу скорее будут частью 1 кластера, а данные в правом верхнем углу скорее принадлежат 2 кластеру.
Конечно, это относительно простой пример. В реальности обычно все бывает немного сложнее.
8. Данные для обучения vs. тестовые данные
Когда у вас есть набор данных, вы можете построить алгоритм прогнозирования. Но как узнать, насколько точными являются полученные прогнозы? Чтобы это узнать, необходим второй набор данных. Это тестовый набор.
Обычно тестовые данные и данные для обучения создаются путем разделения одного полного набора данных (см. рисунок ниже). Первая часть этого набора – для процесса обучения. Эти данные будут использоваться для создания прогнозирующего алгоритма. Второй набор данных - это тестовые данные. Эти неизвестные данные будут использоваться после того, как алгоритм будет создан, для того, чтобы проверить, насколько точными являются прогнозы алгоритма.

Если эти два набора данных не разделяются, то проверять точность созданных моделей будет необходимо на тех же данных, которые были использованы для создания алгоритма в первую очередь. И это фундаментальная ошибка, которая может привести к тому, что называется «переобучением».
9. Переобучение
Не все модели прогнозирования пригодны.
Машинное обучение - комплексный метод, и он может обеспечить очень подробный анализ. Но именно из-за этого уровня детализации он подвергается риску «переобучения». Это означает, что любой может создать алгоритм, который способен предсказать свои данные с довольно идеальной точностью!
Возьмите пример с данными о 14-дневном метеорологическом прогнозе, который упоминался ранее.


На этом рисунке показано дерево решений, которое может предсказать, хотели ли дети играть на свежем воздухе в течение последних 14 дней со 100-процентной точностью. Эта модель явно очень детализирована, поскольку она адаптирована к нашему конкретному набору данных.
Сравните эту модель с моделью, приведенной ниже. Нижеприведенная модель проста и понятна. Когда ожидается солнечная погода, дети, вероятнее всего, будут на детской площадке. Когда прогноз дождливый, дети вряд ли выйдут на детскую площадку. Эта модель довольно проста и понятна с учетом имеющихся знаний.
Вышеупомянутая же модель нереально сложна. Мы рассматривали данные всех 14 дней (рядов) для построения этой модели. Однако, наша модель имеет 19 (!) возможных исходов событий. Это означает, что возможных исходов событий больше, чем изначально вкладывается в данные. Другими словами, эта модель слишком сложна.
Проблема переобучения заключается в том, полученная модель идеально «подходит» к данным, которые использовались для ее создания. Однако, на практике она по сути не применяется. Если добавить новые данные в эту модель, точность будет тотчас же снижена. Точность гораздо более простой модели, представленной ниже, скорее всего, останется неизменной.

Поэтому не поддавайтесь тому обману, когда люди говорят, что у них есть прогностическая модель, которая может создать очень точные прогнозы! Под «капотом» данная модель, вероятно, не имеет такой ценности.
9 понятий, которые рассмотрены в данной статье, очевидно, не охватывают все, что вам нужно знать касательно HR аналитики. Надеюсь, они помогут вам лучше понять, о чем говорят ваши аналитики или консультанты. Если вы знаете какие-либо аспекты, которые также должны быть в этом списке, не стесняйтесь добавлять их, публикуя комментарий.
__________________________________________________________
На этом все, читайте нас в фейсбуке и телеграмме
Комментариев нет:
Отправить комментарий